BigQueryとETLの連携メリットとツールの選び方をわかりやすく解説

今日のビジネスにおいて、データは最も重要な資産の一つです。しかし、社内の様々なシステムに散在するデータを集約し、分析できる状態に整えるプロセス(データ整備)は、手作業で行うと非常に手間と時間がかかり、非効率になりがちです。
そこで、データウェアハウス(DWH)の代表格である BigQuery と、データ収集・加工を自動化する ETLツール の連携が不可欠になります。この連携こそが、煩雑なデータ整備プロセスを一変させ、データ活用を効率的かつスムーズにする鍵です。
本記事では、データ活用を推進する企業担当者の方々へ向け、 BigQueryとETLツールの基礎から、連携によって得られる劇的な効果、そして実践的な導入手順を徹底的に解説します。特に、自社に最適なツールを選定するための具体的な4つのポイントを提示し、データ活用を次のステージへ進めるための実践的なガイドを提供します。
目次
- BigQueryとは?
- BigQueryの主な機能
- ETLツールとは?
- BigQueryとETLを連携しデータ移行する方法
- BigQueryとETLツールを連携させるメリット
- BigQueryと連携可能なETLツールの選び方
- BigQueryとETLツール連携の事例
- BigQueryとETLツールを連携させるならReckoner
BigQueryとは?
BigQueryは、Google Cloudが提供するデータウェアハウス(DWH)です。
データウェアハウス(DWH)としてのBigQuery
データウェアハウス(DWH)とは、企業の日々の業務で発生し、蓄積される膨大な量のデータを、分析や意思決定のために格納・管理することに特化したシステムのことです。
BigQueryは、ビッグデータであっても非常に速い速度で集計できるという特徴を持ちます。
BigQueryの活用シーン
BigQueryの真価が発揮されるのは、「膨大なデータ」と「高速な集計・分析」が求められる場面です。具体的な活用シーンの例は以下の通りです。
- 膨大なアプリデータや大規模なECサイトのデータ集計(利用者データ・操作ログなど)
- 大規模サイトにおけるGoogleサーチコンソールのキーワードのグルーピング
- 産業用途における機械ログの収集
また、BigQueryはクラウド型のサービスなので、導入のハードルが低く、すぐに使い始めることができるのも大きな特徴です。
BigQueryの主な機能
BigQueryは単なるデータ置き場ではなく、大規模なデータ分析を効率的に行うための多彩な機能を備えています。その主な機能は以下の通りです。
- データ分析
- データ保存(ストレージ)
- Googleツールとの連携
データ分析
BigQueryの最大の特長は、その圧倒的なクエリ実行速度と分析能力の高さにあります。
膨大なデータの分析力
BigQueryは、従来のシステムでは処理が難しかったペタバイト級のデータ(数億件以上のレコード)でも、効率的に分析できる設計になっています。蓄積された大規模なアプリログやECサイトの取引履歴など、企業の全データを対象とした分析を可能にします。
高速な分析
Googleの分散処理技術を活用し、複雑な集計や結合処理を極めて迅速に実行します。これにより、分析結果が出るまでの待ち時間が大幅に短縮され、PDCAサイクルを高速で回すことができます。
リアルタイムに近い分析の実現
BigQueryにデータを連携するETL/ELTツールやストリーミング機能を利用することで、リアルタイムに近いデータを取り込み、ほぼ遅延なく分析にかけることが可能です。例えば、キャンペーン実行中の効果測定や、緊急性の高いシステム監視など、「今」のデータに基づいた意思決定を強力にサポートします。
データ保存
BigQueryは、データ分析基盤の土台となる「データ保存」の面でも、従来のシステムにはない大きなメリットを提供します。
事実上の容量無制限
BigQueryはペタバイト(数千テラバイト)級のデータでも格納でき、データ量が増えてもシステム側で自動的に容量が拡張されます。これにより、企業の成長やデータ量の増加を気にせず、すべてのデータを安心して蓄積し続けられます。
運用・管理の手間が一切不要
BigQueryは「フルマネージド」サービスです。サーバーの増設やインフラのメンテナンス、ストレージの最適化といった煩雑な作業は、すべてGoogle側が担当します。管理に時間を割く必要がなく、データ活用の企画や分析業務といった本質的な活動に集中できます。
長期保存に強いコスト効率
BigQueryのストレージ料金は、データのアクセス頻度に応じて最適化される設計になっています。具体的には、90日間アクセスがないデータは「長期保存」と見なされ、料金が自動的に大幅に割引されます。過去の重要なデータを低コストで保管し続けられるため、データ活用の幅が広がります。
Googleツールとの連携
BigQueryの大きなメリットの一つは、Googleが提供する様々なツールやサービスとシームレスに連携できる点です。これにより、分析結果を組織全体で共有・活用するプロセスが劇的に効率化します。
BigQueryと特に連携性の高いGoogleサービスは以下の通りです。
- Google Analytics 4 (GA4)
- Looker
- Looker Studio
- Googleスプレッドシート
- Googleサーチコンソール
- Google Cloud Storage (GCS)
- Google Gemini
ETLツールとは?
ETLとは、「Extract(抽出)」、「Transform(変換・加工)」、「Load(格納)」の頭文字を取った略語です。これは、企業内にバラバラに存在するデータを一つに集め、分析しやすい状態に整えるための一連のプロセス、またはその仕組みを提供するツールを指します。
ETLツールは、以下の3つの機能で、データの統合管理を実現します。
Extract(抽出)
必要なデータを社内の様々なシステム(SaaS、データベース、ログファイルなど)から取得します。
各部門やシステムが独自のデータを抱え込み、組織全体での横断的なデータ活用が極めて困難になるのです。このサイロ化されたデータを短期間ですべて統合することは、ETLプロセスの構築に多大なリソースを割くこととなります。
Transform(変換・加工)
取得したデータを、分析に適した形式や、格納先のルールに合わせて整形、クレンジング(重複・欠損値の除去)します。
Load(格納)
変換・加工を終えたデータを、BigQueryのようなデータウェアハウスや他のシステムに書き込み(格納)ます。
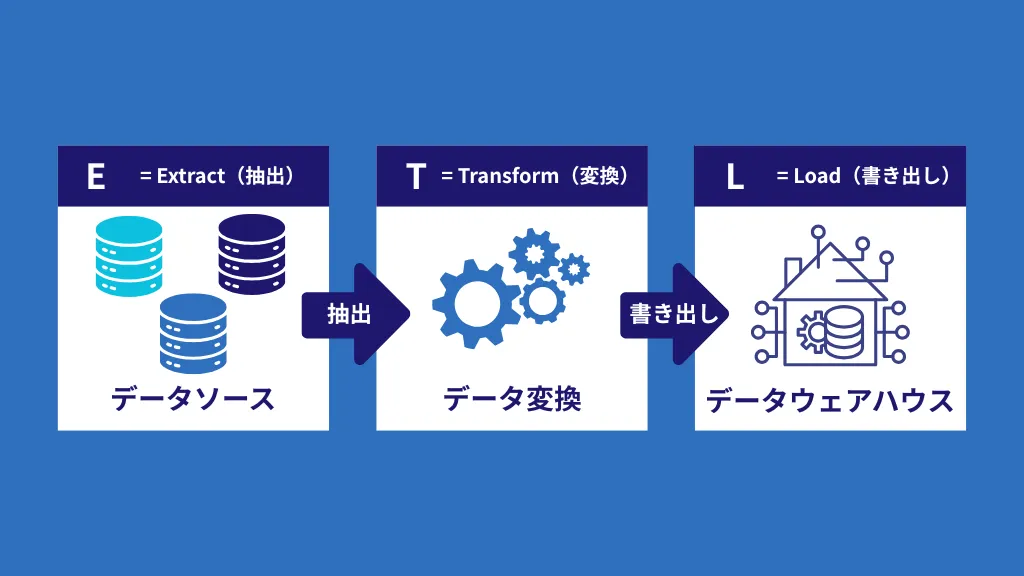
BigQueryとETLを連携しデータ移行する方法
BigQueryとETLツールを連携させることは、社内のさまざまな場所に散らばっているデータを、分析に適したBigQueryへ効率的かつ自動的に移行し、データ活用の基盤を確立する上で不可欠です。この連携を実現し、データ移行を安定させるための具体的な手順は、ETLの基本要素である以下の3つのステップに沿って進められます。
- データ抽出 (Extract)
- データ変換 (Transform)
- データ書き出し (Load)
1.データ抽出(Extract)
データ移行の最初のステップは、BigQueryに取り込みたい元データを、社内外のさまざまなシステムから「抽出」することです。
ETLツールを利用することで、複数の異なるデータソース(例:社内のRDB、SaaSの顧客データ、Google広告の運用データ、ログファイルなど)から、必要なデータを容易に、かつ一括で取得することができます。手動でのデータダウンロードやシステムごとの個別開発が不要になるため、作業が大幅に効率化されます。
また、単にデータを取得するだけでなく、多くのETLツールでは、抽出時にデータの品質確保や妥当性検証を行う機能も備えています。例えば、必須項目に欠損がないか、データ型が正しいかといったチェックをかけながら抽出します。これにより、後の分析段階でエラーが発生するリスクを減らし、データ活用の基盤となるデータの信頼性を高めることができます。
2.データ変換(Transform)
次に「データ変換(Transform)」を行います。このステップでは、抽出した生のデータをBigQueryのようなDWH(データウェアハウス)に書き出しやすく、かつ分析に最適な形へと加工します。
異なるシステムから抽出されたデータは、そのままではBigQueryのテーブル構造やデータ形式に合わないことがほとんどです。ETLツールの変換機能は、日付形式や数値形式の統一、不要なデータの削除、データ型の調整などを行い、ターゲットとなるDWHにスムーズに格納できるようにデータを整形します。
また、単なる形式の調整に留まらず、複雑な分析を可能にするための高度な加工も行えます。
データの統合・結合(マージ)
顧客IDなどのキー情報をもとに、複数のシステムに分散しているデータ(例:購入履歴と会員情報)を一つに結合し、分析の準備を整えます。
集計・要約
大量のトランザクションデータから、日別や月別の売上合計や平均値などを計算し、分析負荷の低い「サマリーデータ」を作成します。
クレンジングと品質向上
データの欠損値の補完や重複データの除去を行い、分析結果の正確性を高めるためのデータクレンジングを実施します。
3.データ書き出し(Load)
最後は、「データ書き出し(Load)」を行います。変換・加工を終えたデータをターゲットであるBigQueryへ格納(インポート)するステップです
BigQueryが提供するデータインポート機能を使うこともできますが、ETLツールのLoad機能を利用することで、自動的かつスムーズに行えます。ETLツールは、BigQueryの接続仕様に合わせて最適化された方法でデータを提供するため、大量のデータを安定して、そして高速に書き出すことができます。
従来、ETLプロセスは、システムごとの接続やデータ変換ロジックを、すべてプログラミングによって個別に実現していました。しかし、この方法はデータの種類や量が増えるたびに膨大な工数と高い専門性を必要としました。 現在、多くの企業で「ETLツール」が注目を集めているのは、この煩雑なプログラミング作業をノーコードまたはローコードでGUI上から設定・実行できるようにし、データ連携にかかる時間とコストを劇的に削減できるからです。
BigQueryとETLツールを連携させるメリット
BigQueryの持つ高速な分析能力と、ETLツールの持つ自動的なデータ統合・加工能力を組み合わせることで、データ活用プロセスは劇的に改善されます。手作業によるデータ整備の限界を超え、企業は「データを集めるフェーズ」から「データを活用して成果を出すフェーズ」へと移行できるようになります。
ここでは、両ツールの連携によって具体的に実現する、データ活用を成功に導く3つの主要なメリットについて詳しく解説します。
開発コスト削減
BigQueryとETLツールの連携がもたらす最大のメリットの一つは、データ基盤構築・運用の開発コストと工数の劇的な削減です。
ノーコード・ローコードによる開発時間の短縮
従来のデータ連携は、各システムとBigQueryとの接続ロジックやデータ変換処理を、プログラミング言語を用いて個別に開発する必要がありました。しかし、ETLツールの多くは、ノーコード(プログラミング不要)またはローコードでデータ連携のパイプラインを設計・開発できます。これにより、開発時間が大幅に短縮され、システム開発における人件費や期間コストを削減できます。
専門人材の工数削減
データ連携のプログラミングには、データベースやクラウド環境に関する深い知識を持つデータエンジニアの専門的なスキルが不可欠でした。ETLツールを活用することで、複雑な連携処理をエンジニアでなくても設定可能になるため、データエンジニアやデータアナリストの工数削減が期待できます。これにより、彼らはインフラ構築ではなく、データの分析やビジネス改善といった本来の業務に集中できるようになります。
このコスト削減効果は、特にデータソースが多かったり、連携頻度が高かったりする企業にとって、大きな経営的なメリットとなります。
定型作業の自動化
BigQueryとETLツールを連携することで、データ活用の現場における非効率な定型作業から解放され、業務の質と効率が同時に向上します。
データ入力・更新作業の自動化による工数削減
毎日のレポート作成のために、複数のシステムからデータを抽出し、加工し、BigQueryへ手動でインポートする作業は、時間とリソースを大きく消費します。ETLツールは、このデータ抽出・変換・格納の一連のプロセスを完全に自動化します。一度設定すれば、後はツールが定期的かつ正確にデータを移行・更新するため、担当者の工数が劇的に削減されます。
人的ミスの回避とデータ品質の向上
手作業によるデータ入力や加工は、データの誤変換や誤った更新、ファイル操作中のデータ喪失といった人的ミスが発生するリスクが常に伴います。ETLツールは、あらかじめ設定されたロジックに基づいて機械的に処理を実行するため、これらのヒューマンエラーを根本的に排除できます。これにより、データの信頼性が担保され、BigQuery上に蓄積される分析データの品質が安定します。
定型作業をツールに任せることで、担当者はルーティンワークから解放され、より創造的で価値の高い「データ分析」や「施策の立案」に集中できるようになります。
高いセキュリティ性
データを外部に転送・格納する際、企業の機密情報が関わるため、セキュリティは最重要項目となります。BigQueryと連携する多くのETLツールは、このセキュリティ面でも大きなメリットを提供します。
機密情報送信リスクの低減
ETLツールを利用することで、データ連携のプロセスが一元管理され、人手を介さずに自動でデータが転送されます。これにより、手動でのデータ移動や、不適切なファイル共有による機密情報の漏洩リスクを大幅に低減できます。
安全性の高い転送プロトコルの利用
信頼性の高いETLツールの多くは、データ転送の形式としてSSH(Secure Shell)などの暗号化されたプロトコルを介しています。SSHは、インターネット上でデータを安全に送受信するための仕組みであり、これにより、転送途中のデータが第三者に盗聴されたり、ハッキングされたりする可能性を極めて低く抑えることができます。
高いセキュリティ基準を満たすETLツールを導入し、BigQueryと連携することで、企業はデータ活用の促進と同時に、大切な社内機密データの保護を両立させることが可能になります。
BigQueryと連携可能なETLツールの選び方
データ活用の成功は、連携するETLツールの選定にかかっていると言っても過言ではありません。市場には多様なETLツールが存在するため、自社のデータソース、要件、予算に合ったものを選ぶことが非常に重要です。
ここでは、BigQueryとの連携を前提としたETLツールの選定において、失敗を避けるために必ず確認すべき4つの主要なポイントをご紹介します。
クラウドとオンプレミスのどちらが適しているか
ETLツールは、その提供形態によって主にクラウド型とオンプレミス型の2種類に分けられます。BigQueryとの連携を検討する際、この選択は運用コスト、セキュリティ、そして管理の容易さに大きく影響します。
クラウド型ETLツール
クラウド型はインターネット経由で利用します。データの抽出、変換、格納といった一連のETL処理は、すべてクラウド上で行われます。
オンプレミス型ETLツール
オンプレミス型は、自社でサーバーやネットワークなどのインフラを保有し、その上でETLツールをインストールして稼働させます。
どちらの形態を選ぶかは、「データがどこにあるか」「どこまでのセキュリティ要件が必要か」「インフラ管理に割けるリソース」によって判断することが重要です。
さらに詳しい情報や具体的なツール比較については、以下の記事も参考にしてください。
ツールの利用料金は予算内か
ETLツールを選定する際、機能やセキュリティと並んで、「料金体系」の検討は非常に重要です。利用料金はツールの形態や提供会社によって大きく異なるため、初期費用とランニングコストを総合的に評価する必要があります。
料金体系の種類と選定のポイント
ETLツールの料金体系は、主に以下の2種類に大別されます。
1.月額定額制
データ量や処理回数に関わらず、毎月一定の料金を支払う方式です。利用量が多い、あるいは利用量が安定している場合にコストメリットが出やすいことがあります。
2.従量課金制
処理したデータ量や、ETLジョブの実行回数など、利用実態に応じて料金が変動する方式です。データ活用をスモールスタートしたい、または利用量が季節によって大きく変動する場合に適しています。
総合的なコスト検討の必要性
料金を評価する際は、月々のランニングコストだけでなく、初期設定費用やサポート費用も含めた総合的な検討が必要です。想定されるデータ量の増加や利用頻度の変化を考慮し、中長期的な視点から予算内に収まるかを判断しましょう。
また、製品によっては無料版や試用版が提供されています。データ量や処理回数に制限を持っている場合が多いため、小規模な検証やPoC(概念実証)に有効です。
機能と価格のバランス
ETLツールは多機能になればなるほど、価格が高くなる傾向があります。自社のデータ活用目的を明確にし、本当に必要なデータソースへの接続や加工機能に絞った、シンプルなツールを選ぶことも、コスト効率を高める賢明な選択肢となります。
利用できるコネクタ、データ連携ソースは十分か
ETLツールを選定する際、最も基本的な、そして最も重要な確認事項の一つが、「自社で利用しているデータソースと接続できるか」という点です。BigQueryがどんなに高性能でも、データを取り込めなければ意味がありません。
ETLツールが提供するコネクタとは、特定のシステム(例:Salesforce、SAP、Oracle DB、各種SaaSなど)に接続し、データを入出力するためのインターフェース機能です。導入を検討しているETLツールが、現在、自社で稼働している業務システムやデータベースとの互換性(つまり、専用のコネクタ)を持っているかを必ず確認する必要があります。互換性がない場合、個別開発が必要になり、結果的に導入コストと時間が大幅に増大してしまいます。
また、IT環境は常に変化するため、現在だけでなく将来的に導入を検討しているシステムや、データ連携が必要になるであろうSaaSなどを見越して評価することが賢明です。 汎用性が高く、多くの主要なデータソースに対応しているツールを選ぶことで、将来的に新しいデータソースが増えた際の拡張性が確保され、データ活用の幅が広がります。
処理可能なデータ量は十分か
ETLツールは、それぞれが持つアーキテクチャや設計に基づいた独自のデータ処理の限界を持っています。そのため、導入を検討する際は、自社が処理したいデータ量をツールが安定的に処理できるかを事前に確認することが極めて重要です。
機能が優れていても、実際に処理できるデータ量や処理速度が自社の要件を満たさなければ、ボトルネックとなってしまいます。特に、日々のトランザクションログやIoTデバイスからのデータなど、データ量が急増する可能性がある場合は、その増加に対応できるスケーラビリティがあるかを重視する必要があります。
自社が持つ現在のデータ量と連携頻度を正確に把握し、その上でETLツールが定める処理能力のスペックと比較し、選定することが重要です。
操作性はよいか、サポート体制は手厚いか
機能、コスト、性能が優れていても、現場で使われなければETLツールの導入は成功しません。ツールが「使いやすいか」、そして「困ったときに助けてくれるか」という点も、選定において非常に重要な要素です。
使いやすさ(操作性)の評価
ETLツールは、データエンジニアだけでなく、データ分析担当者など非エンジニア層が操作する機会も増えています。そのため、自社の利用者を想定し、直感的なGUI(グラフィカルユーザーインターフェース)で、プログラミング知識がなくてもデータ連携フローを設計できるかを確認しましょう。操作性が良ければ、ツールがスムーズに社内に浸透しやすくなり、データ活用のスピードが上がります。
充実したサポート体制の確認
データ連携の過程では、システム障害やデータソース側の仕様変更など、予期せぬトラブルが発生することがあります。このような「困った場合」に、迅速に問題を解決できるよう、ツール提供元による手厚いサポート体制があるかを確認することが重要です。具体的には、日本語でのサポートの有無、対応時間、ナレッジベース(ヘルプページ)の充実度などを評価しましょう。
ツール導入後の定着と安定運用のためには、操作する人の視点に立ち、利用者がストレスなく使いこなせる環境を整えることが肝心です。
BigQueryとETLツール連携の事例
ここまで、BigQueryとETLツールの基礎知識、連携方法、そして連携のメリットやツール選定のポイントについて解説してきました。このセクションでは具体的なイメージを持っていただくために、BigQueryとETLツールを連携させ、データ活用を次のステージへと進めた企業の成功事例をご紹介します。
auコマース&ライフ様の事例
BigQueryを「データ集約のハブ」として活用
導入の目的
システムの分散化によるデータ分析業務の非効率性を解消し、データドリブンな営業活動を推進すること。
導入前の課題
- サービスごとにデータベースが分散し、データ収集・加工に多大な時間と労力がかかっていた。
- SQL抽出やバッチ処理など、コーディング知識があるメンバーしか対応できない業務が多く、属人化していた。
連携ワークフロー
複数の社内システムからデータをまず BigQuery および Amazon S3 に集約。
その後、ETLツール(Reckoner)を利用して、BigQueryから必要なデータを抽出し、加工を加えた上で、Salesforceへ連携し、営業活動に活用。
連携の効果
- データ連携や加工処理を非エンジニア部門(営業部門)自身で完結できるようになった。
- データ分析業務が標準化され、属人化を解消。分析や施策立案に割ける時間が増加した。
- 最新の顧客アンケート結果をスプレッドシート経由でSalesforceへ自動連携し、カスタマーサポート活動の改善に貢献。
インタビュー全文は以下からご覧いただけます。
BigQueryとETLツールを連携させるならReckoner
ここまでBigQueryとETL連携の重要性、具体的な手順、そしてツール選定のポイントを解説してきました。BigQueryの高速な分析能力を最大限に引き出し、データ活用を成功させるためには、ノーコードで連携を自動化できるETLツールの選定が最も重要です。
もし、貴社が「BigQueryへのデータ統合を迅速かつ低コストで実現したい」「データ連携の属人化を解消したい」とお考えであれば、ETLツール「Reckoner(レコナー)」がその強力な解決策となります。
Reckonerで実現するBigQuery連携ワークフローの例
Reckonerは、BigQueryをデータ統合のハブ(中心)として活用するワークフローを容易に実現します。
Extract(抽出)
社内の複数のデータベース、各種SaaS(Salesforceなど)、クラウドストレージ(AWS S3など)から、必要なデータをReckonerが抽出します。
Transform (変換・加工)
抽出したデータを、BigQueryへ安定的に集約・格納します。
BigQueryに集約されたデータを、Reckonerがノーコードで加工・変換し、BIツールや営業部門が利用するシステム(Salesforceなど)へ必要な形で自動的に供給します。
Load(格納)
抽出したデータを、BigQueryへ安定的に集約・格納します。
このようにReckonerを活用することで、煩雑なデータ加工・連携のプロセスが自動化され、BigQueryを中心とした「データ分析の標準化」が実現します。
ReckonerでBigQuery連携を成功させるメリット
開発コストと工数の大幅削減
ノーコード・ローコードでデータ連携フローを設計できるため、プログラミング開発が不要となり、データエンジニアの工数を削減し、開発期間を大幅に短縮します。
非エンジニアによる運用
直感的な操作画面(GUI)により、ITの専門知識がない営業部門やアナリスト自身でもデータ連携を構築・運用でき、データ分析の属人化を解消します。
BigQueryとの高い親和性
BigQueryの特性を活かした高速かつ安定的なデータ連携を実現し、リアルタイムに近いデータ分析環境の構築をサポートします。
人的ミスの回避
定型的なデータ入力・更新・加工を自動化することで、手作業によるデータの誤変換や誤った更新を防ぎ、データ品質を維持します。
BigQueryの活用・データ連携をご検討の方へ
本記事で解説したように、BigQueryとETLツールを連携させることは、データドリブン経営を実現するための第一歩です。
自社に最適なETLツールの選定や、BigQueryを活用したデータ基盤構築でお困りの方は、ぜひお気軽にご相談ください。
著者








