ChatGPTで集計すると数値がブレる理由と、正しい使い分け

「先月はChatGPTで集計したら¥12,450,000だったのに、今月同じ手順でやったら¥12,380,000になった」
このような経験はありませんか?データドリブン経営が叫ばれる今、AIツールを使って集計・レポート作成を効率化しようとする現場は急増しています。しかし、AIに集計を任せると数値がブレるという問題が各所で起きはじめています。
本記事では、なぜChatGPTなどの生成AIで集計すると数値がブレるのか、そのメカニズムを解説し、AIとデータ処理ツールの正しい使い分けについて説明します。
目次
Q:なぜChatGPTで集計すると毎回数値が違うのか?
A:ChatGPTをはじめとするLLM(大規模言語モデル)は、確率的にトークンを選択して回答を生成します。同じプロンプトを送っても、内部では毎回わずかに異なる計算経路をたどるため、出力結果が変わります。
これは「temperature」「top-p」と呼ばれるパラメータによって制御されており、ランダム性がゼロではない限り、数値の揺らぎは避けられません。
「再現性」が求められる集計業務にとって、これは根本的な問題です。
「ブレる数値」が生まれる3つのメカニズム
1. 確率的サンプリングによる揺らぎ
LLMは次のトークンを確率分布から選択します。計算式が同じでも、文脈の読み方が微妙に変わるだけで出力値が変動します。特に複数ステップの集計(「先月の売上を部門別に集計してから合計する」など)では、途中のステップでのズレが最終値に影響します。
2. プロンプト依存の曖昧さ
集計の条件はすべてプロンプトの文章で伝えるしかありません。「先月の売上」「当月比」「前期比」といった言葉は、担当者によって解釈が異なります。
- 「先月」=前月1日〜末日?それとも直近30日?
- 「売上」=受注金額?請求金額?入金金額?
これらの定義がプロンプトに書かれていなければ、AIは毎回異なる解釈をする可能性があります。その結果、担当者が変わるたびに数値も変わるという状況が生まれます。
3. ハルシネーション(事実誤認)
AIは存在しないデータや数値を「もっともらしく」生成することがあります。これをハルシネーションと呼びます。
集計業務でのハルシネーションは特に発見が困難です。なぜなら、数値が完全に誤っていても自然な文体で出力されるため、一見すると正しい結果に見えるからです。
こんな場面でAI集計は特に危険
以下のような業務でAIに集計を任せると、数値ブレのリスクが高まります。
- 月次・週次の定期レポート — 毎回同じ結果が必要な業務
- KPIの確定値の算出 — 経営会議で使う数字
- 複数ソースのデータ突合 — SFA・MA・基幹DBを組み合わせる集計
- 監査が必要な財務データ — 証跡・再現性が求められる数値
逆に言えば、これらの業務にAIを使うことは、報告数値の信頼性を損なうリスクと隣り合わせです。
では、AIは数値化業務に使えないのか?
そんなことはありません。AIが真価を発揮するのは、確定した数値の上で「意味を読み解く」作業です。
| 向いている ✅ | 向いていない ❌ |
|---|---|
| 集計結果からインサイトを抽出する | 定期レポートの集計値を算出する |
| 数値の変化を自然言語でサマリーする | KPIの確定値を計算する |
| 異常値や傾向をパターンとして説明する | 複数ソースの突合・名寄せ |
| テキストデータから定性情報を整理する | 監査に耐える数値の再現 |
つまり、「確定値を作る工程」と「意味を作る工程」を分けて設計することが重要です。
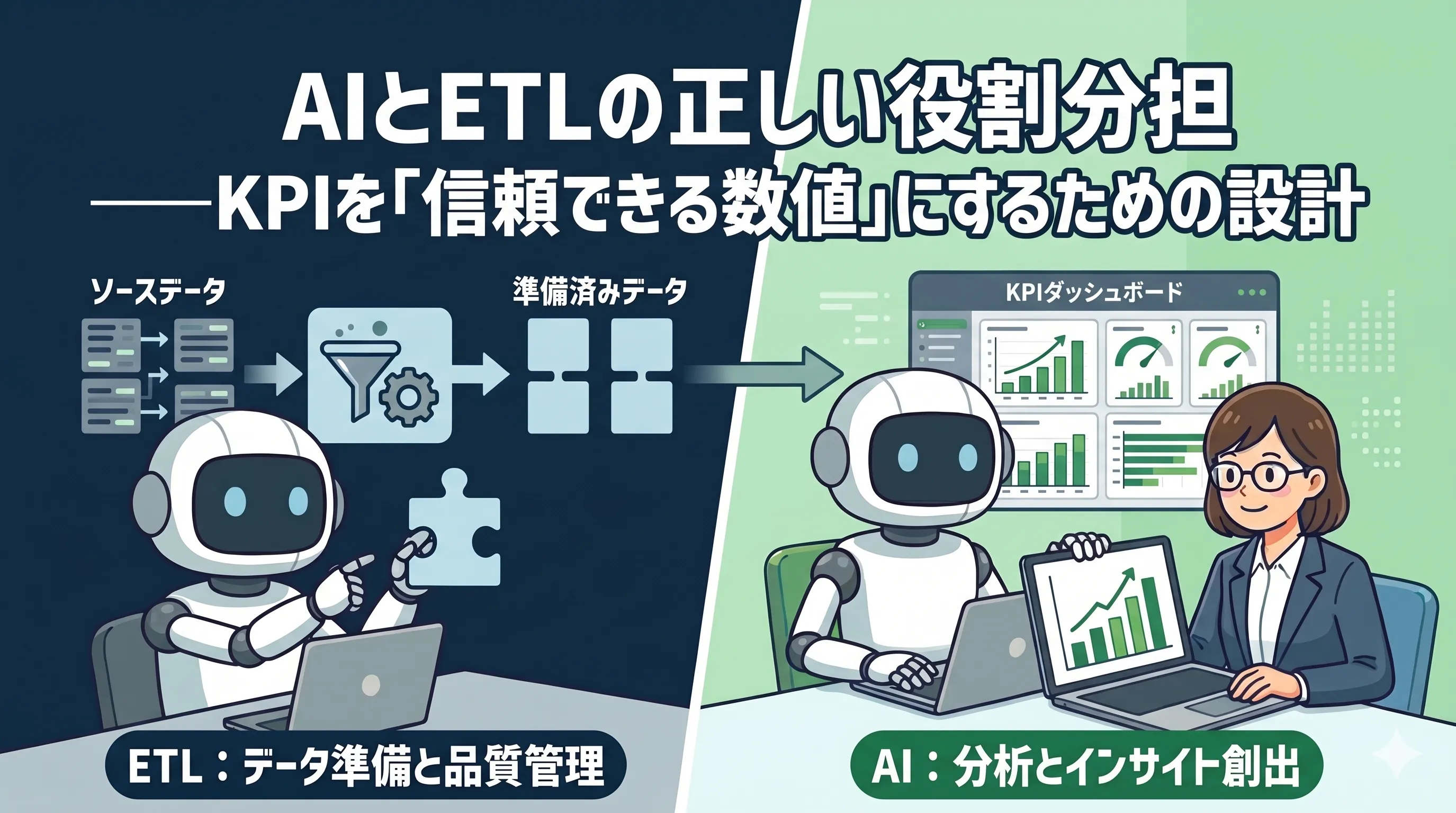
「確定値を作る工程」はETLツールに任せる
数値の再現性・正確性を担保するために設計されたのが、ETL(Extract/Transform/Load)ツールです。
ETLツールは以下の特性を持ちます。
再現性の保証
同じ入力・同じロジックであれば、いつ実行しても同じ結果を返します。temperature も top-p も存在しません。
ルールの明示化・共有
集計ロジックはコードやフローとして定義されます。「何をどう計算したか」が可視化され、担当者が変わっても引き継げます。
自動化・定期実行
スケジュール設定で毎日・毎週・毎月の集計を自動実行。人的ミスや作業漏れがなくなります。
監査対応
データの来歴(データリネージ)が記録され、「このKPIはどのデータソースからどういうロジックで算出されたか」を証明できます。
理想的なデータ活用の分業体制
データソース(SFA/MA/基幹DB)
↓
Reckoner(ETL)
・突合・名寄せ
・集計・KPI算出 ← ここは必ずルールベースで
・確定値の出力
↓
AI(LLM)
・傾向・異常の分析
・自然言語でのサマリー ← ここでAIの真価が出る
・インサイト提案
↓
意思決定ETLで「確実な数値」を作り、AIで「意味のある洞察」を引き出す。この分業こそが、信頼できるデータ活用の正解です。
まとめ
- ChatGPTなどのLLMは確率的にトークンを選択するため、集計結果が毎回変わる
- プロンプトに依存した集計は条件の解釈がブレやすく、担当者ごとに数値が違う
- ハルシネーションにより誤った数値が「それらしく」生成されることがある
- 定期集計・KPI確定値・監査対応にはETLツールを使うべき
- AIはETLで確定した数値の上でインサイト抽出・サマリー生成に使うのが正解
次のステップ
本記事の内容をより詳しく解説したホワイトペーパー「数値化の信頼性を守る — AIに任せるべき仕事、ツールに任せるべき仕事」を無料配布しています。失敗シナリオ・業界データ・判断フレームワーク完全版を収録しています。
著者