組織におけるデータ戦略と実践(3): データライフサイクルを見直す

データ戦略を考える上で、データのライフサイクルの見直しや改善は必須のアクションとなります。では、データライフサイクルはどのように分析し、どのように目標を設定すればよいかについて、以下で解説します。
(参考元: Atwal, Harvinder “Chapter 2. 2. Data Strategy.” In Practical DataOps: Delivering Agile Data Science at Scale, edited by Atwal, Harvinder. Isleworth, UK: APRESS, 2020.)
目次
データライフサイクルをギャップ分析する

データライフサイクルとは、データの誕生(データの取得または生成)から死(アーカイブおよび削除)に至るまで、データの単位が通過する段階を指します。データガバナンスだけでなく、データ戦略全体の概念モデルを考える上で、データライフサイクルを以下のような段階を念頭に置くべきとされています。
- キャプチャー(Capture):データの取得(最初のステップ)
- 保存(Store):データの保存
- 処理(Process):ETL、クリーニング、リッチ化などのプロセス経た処理
- 共有(Share):システム間で共有または統合
- 活用(Use):データ共有、もしくは分析(記述的分析、診断的分析、予測的分析、処方的分析)などのアウトプット
- データ利用の終了(End-of-Life):規制要件、コスト、価値の低下などを理由とした終了
データ戦略を考える上で重要なのは、データライフサイクルは輪を描くように直線的に進むものではありません。
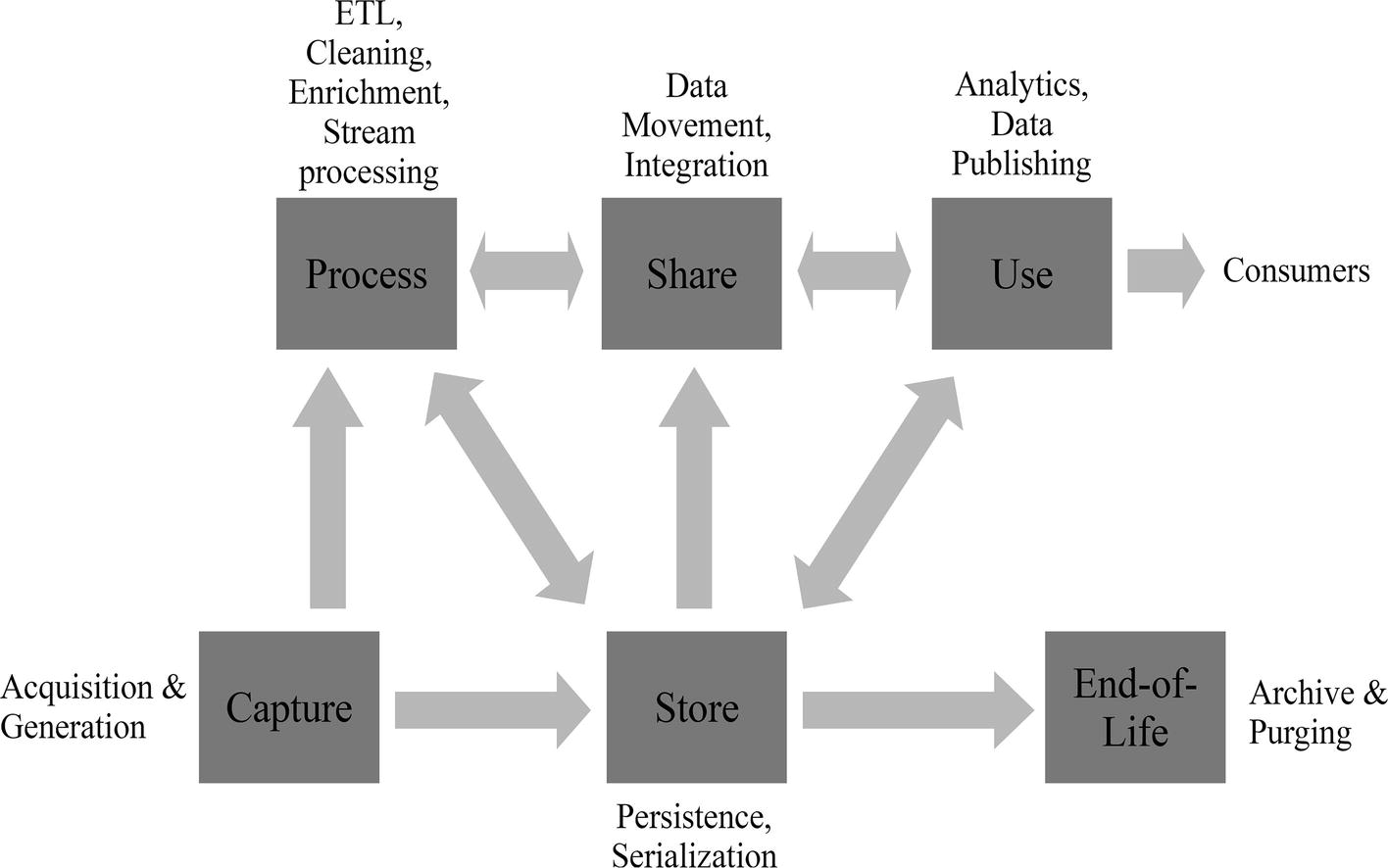
(画像引用元:Figure 2-1., Atwal, Harvinder “Chapter 2. Data Strategy.” In Practical DataOps: Delivering Agile Data Science at Scale, edited by Atwal, Harvinder. Isleworth, UK: APRESS, 2020.)
組織内のデータライフサイクルに対する戦略的な変更を特定するには、現在の能力と、潜在的な分析イニシアチブ(主導的取り組み)の提供を目的としたライフサイクルを通じて各データユニットが行うべき理想的な行程とのギャップを確認する必要があります。
この比較により、ライフサイクルの各段階で行うべき戦略的決定と、分析イニシアチブを効率的に提供するために、人・プロセス・テクノロジーをより適切にサポートするために必要な改善が決断されます。事前に行われた状況分析は、このプロセスを容易にするように設計されています。
分析イニシアチブごとに、データライフサイクルを一度に1つのステージずつ逆方向にパスして、各データユニットが現在どのように移動しているかと比較して、要件をよりよく理解します。
データライフサイクルの各段階におけるデータサイエンティスト・アナリストに期待される役割やデータのあるべき姿はどのようなものがあるでしょうか。以下、説明します。
活用(Use)の段階
データ サイエンティストの役割:
- 機械学習モデルを使用して、複数のソースからのデータを組み合わせて製品の提案を行う。
- モデルを構築するために十分なスペックの環境にいる。
- 本番環境におけるモデルの計画立案・展開を実行する。
データアナリストの役割:
- 結果を追跡するためにBIツールを使用してレポートを作成する。
共有(Share)の段階
データのあるべき姿:
- データはできればデータサイエンティストが必要とする形式 (構造化データの非正規化フラットファイルなど) で、複数のシステムから単一のシステムに移動する。
データ サイエンティストの役割:
- モデルの精度を向上させる可能性が高いため、多数のソースからのデータにアクセスする。
- データ、その場所、およびその内容を特定する。
処理(Process)の段階
データのあるべき姿:
- データは一連のステップで可能な限り迅速にある状態から別の状態に移動する。
データサイエンティストの役割:
- モデルを作成して実行し、測定値を取得するために使用する、データソースからターゲット システムへの ETL パイプラインを構築するデータエンジニアを配置する。
- 処理中に、データを必要な形式に変換し、クリーニングし、機密データをマスクまたは削除する。
- ビジネスイベントデータ形式のデータを持つ。
保存(Store)の段階
データサイエンティストの役割:
- タイムスタンプ、イベント名、イベントタイプ、イベントのトリガーとなった状態の変化の詳細を示すデータを入手している。
キャプチャー(Capture)の段階
データサイエンティストの役割:
- 追加のデータを取得して生成する。
- 新しいイベントデータや内部データを補強する外部データへのアクセスを可能にする。
これらのプロセスは、すべての分析イニシアチブ (または少なくとも十分な見積もられた利点があるすべてのイニシアチブ) に対して繰り返され、ギャップが見落とされないようにします。実践を終えた際には、データライフサイクルの各段階での理想的な要件と、現在の機能との相違点を十分に理解する必要があります。
参考記事:DataOpsチームを作る
データ戦略の目標を定義する

要件と現在の能力をよりよく理解することで、組織はデータ戦略の目的を検討し始めることができます。まず、データ ライフサイクル全体を順方向に進め、各段階で、特定されたギャップをできるだけ多く同時に埋めるために必要なデータ戦略の目標を決定します。
すべての組織は、特定の強みと弱みによって異なります。データ ライフサイクルの各段階での典型的な目的を示しています。
- キャプチャー(Capture)の目的:新しいデータをできるだけ簡単に取得できるようにすることです。これにより、ライフサイクルの残りの過程をできるだけスムーズに進めることができます。
- 保存(Store):潜在的に有用なデータを、プロセス、共有、および使用ステージに役立つ場所、形式、およびストレージ ソリューションにできるだけ多く保存することです。
- 処理(Process)の目的:データ ストリームまたは格納されたデータをあらゆる形式で可能な限り効率的に処理して、使用のために確実に共有できる出力を生成することです。
- 共有(Share)の目的:開発者間でコードを共有するのと同じくらい簡単に、ユーザーとシステム間でデータを共有できるようにすることです。
- 活用(Use)の目的:データを結合し、特定した分析イニシアチブ用のデータ製品を作成し、それらを本番環境に展開し、パフォーマンスを監視するためのハードウェアおよびソフトウェア リソースを確保することです。
- データ利用の終了(End-of-Life)の目的:人為的な容量制限によってデータを制約するのではなく、有用である限りデータを保持することであり、アーカイブされたデータは簡単に取得できる必要があります。また、データ利用者は、データ主体がデータを削除する権利を含め、データを保持できる期間を制限する規制を確実に遵守する必要があります。
データ ライフサイクルの各段階でデータ戦略の目標を設定することで、誰もが何をすべきかを簡単に理解できるようになります。
- 参考記事:【用語集】データガバナンス
まとめ
データライフサイクルのギャップ分析およびデータ戦略の上でデータライフサイクルの各段階における目的の明確化の必要性について説明しました。データライフサイクルを実践していくには、効率的なツールの活用が不可欠です。
弊社が提供するETLツール「Reckoner」は、あらゆるデータソースに対応しており、ワークフローによる直感的な操作でデータ変換や分析が実施可能です。
データ統合に向けた製品の導入や戦略の立案でお悩みの組織様は、ぜひ一度お問い合わせください。ETLツールについて詳しく知りたい、ETLツールの選び方を知りたいという方はこちらの「ETLツールとは?選び方やメリットを解説」をぜひご覧ください。
関連記事
関連記事はありません。




