[2022-2023年版] [初心者向け3分解説] ETLとは何か: 5つのポイントから理解する

ここ最近、データ分析やビッグデータといった文脈で「ETL」という単語を耳にすることが増えてきました。以下では、「3分でETLの概要を正しく理解する」をテーマに、ETLについて分かりやすくお伝えします。
目次
ETLとは何か
ETLとは、データ処理に関する E、T、L の頭文字を組み合わせた略語です。
- Extract: データを抽出する
- Transform: データを加工・変換する
- Load: データをロードする

すなわち、ETLとは「データを抽出し、加工変換し、ロードする」一連の作業を指します。例えば、私たちが普段何気なく行っている以下のような作業も「手動のETL」とも呼べます。
- 「東京都渋谷区渋谷1-1-1」という住所を、「東京都」と「渋谷区渋谷1-1-1」に分割する
- 「03-1234-5678」という電話番号を、「0312345678」や「+81312345678」に変換する
- 「田中」と「一郎」という氏名情報を、「田中一郎」として結合する
- 「10000」と「20000」という売上情報を、「30,000」として統合・変換する
元データはあくまで「東京都渋谷区渋谷1-1-1」「03-1234-5678」「1000000」だが、これらのデータを必要に応じて加工・変換して提供する。または、複数のデータを変換・統合する。
決められた条件に従い、膨大なデータをリアルタイム、またはバッチで処理する。これにより、「処理の正確性」と「高いコストパフォーマンス」を実現する。これが「ETL」です。
ETLツールとは何か
大量のデータを、様々なデータソースから取得し、ロード先のシステムに最適化されたデータに変換・加工する。ETLは、人手では到底できない作業を機械的に行うことに価値があります。
ETLの必要性については、「個人」と「企業・組織」のデータ変換・加工の違いを理解すると話が早いです。

個人の年賀状用住所データであれば、変換・加工が必要になっても数十件、数百件程度で済みますので、手動でも対応可能です。また、年に一度程度しか発生しない処理なので、継続的に工数がかかり続けることはありません。
しかし、企業や組織が管理するデータは数百万件、数千万件、はたまた数億件以上を超えるデータとなる場合があります。また、こうしたデータはリアルタイムや日時での更新が必要になるものも多く、人手で行うには「正確性」と「コストパフォーマンス」の両方を満たすことができません。
また、管理するデータ項目も多岐に渡ります。以下はその一例です。

さらに、元データが所在する場所(データソース)も多岐に渡ります。
- 会計ソフト
- 営業支援ソフト(SFA)
- 顧客管理ソフト(CRM)
- マーケティング自動化ツール(MA)
- Web解析ツール
- データベース
- データウェアハウス
- 各種SaaSなど
このため、データ数、データ項目、データソースが違うことにより、以下のようなデータ連携が必要となります。
- 「元データAを、システムBとCとDで利用する」
- 「BとCとDでは、それぞれデータフォーマットが違うので別々に変換が必要」
- 「BとCは、日単位の更新でよいが、Dは5分ごとの更新が必要」
このため、複数のデータソースからデータを取得し、各出力先に合わせてデータを最適な形で変換・加工し、必要なタイミングで各システムにロードできるETLツールが必要となり、多くの業種・業態で利用されるようになりました。
データの収集
オブザーバビリティでは、監視対象となるシステムから多種多様なデータを収集する必要があります。データはクラウド上に構築した仮想マシンやコンテナ、SaaSで利用しているシステムのデータ、社内で利用している機械からのデータ、ユーザーが利用する端末のデータなど様々な機器からのデータが対象です。
オブザーバビリティの実現には、あらゆるデータを収集していくのが必須となるため、対象の洗い出しや必要なデータを把握するのが重要です。ただし、全てのデータを収集するのは現実的でない場合があるため、必要なデータを取捨選択することが重要です。
ETLツールを利用する5つのメリット
では、企業や組織がETLツールを利用するメリットは何でしょうか。5つのポイントから見ていきましょう。
1.専門的な知識がなくても利用できる
ETLツールの中には、プログラミング知識なしに利用できるように設計された製品もあります。例えば、当社のETLツール「Reckoner」(レコナー)を例にあげると、ドラッグ&ドロップで「データソース」「処理内容」「出力先」を選択し、画面上で入力するだけで、データ変換・加工を実施できます。

これは、専門的な知識を持つエンジニアに都度データ取得を依頼しなくてもよくなることを意味します。非エンジニアの担当者にとっては、自分が必要なタイミングでデータを変換・加工を行えることを意味します。
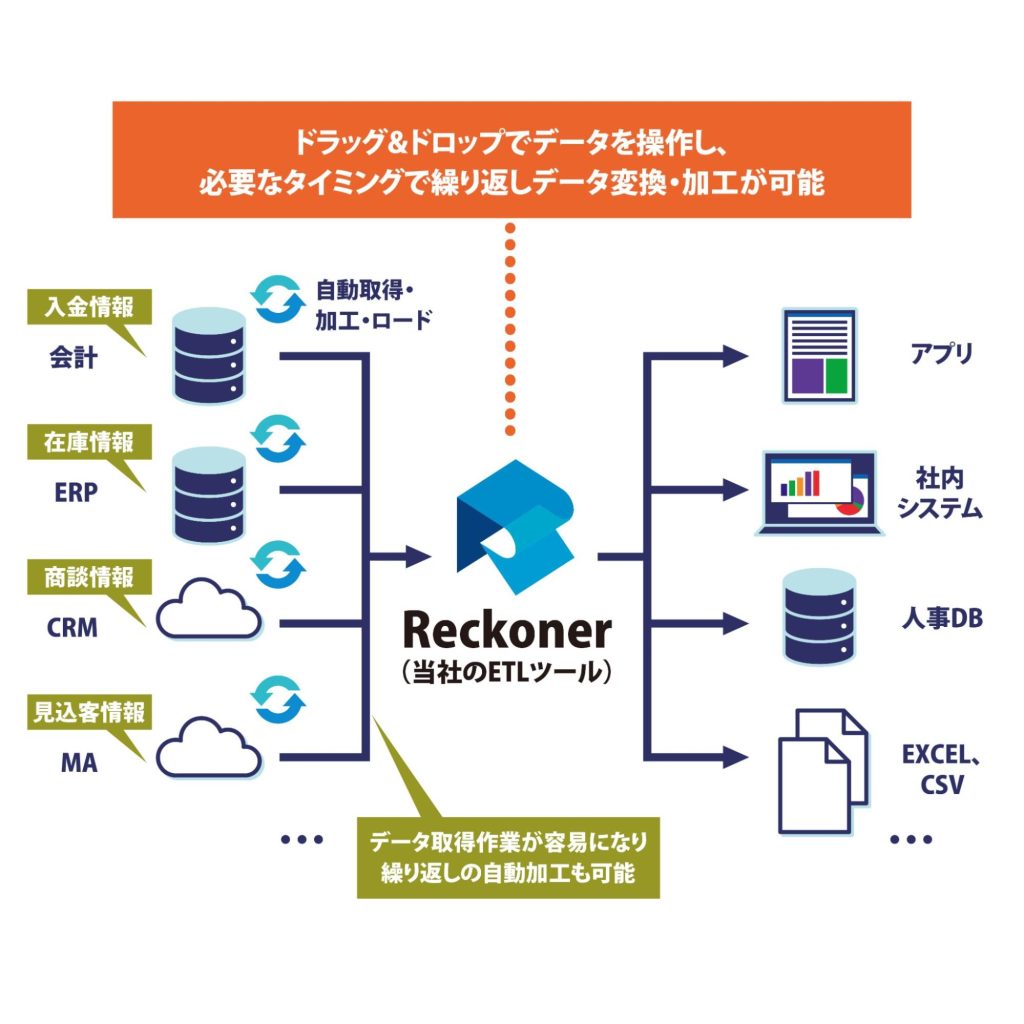
そしてエンジニアにとっては、データ取得・加工といった業務に時間を割かずに済み、より優先度の高い業務に注力できるようになります。
2.データの変換・加工時のヒューマンエラーがなくなる
人の手でデータを加工する場合、ヒューマンエラーから逃れることはできません。ヒューマンエラーにより、「変換したつもりが変換されていなかった」「一部しか変換されていなかった」「間違ったデータが挿入されてしまった」といったデータの変換・加工ミスが発生しがちです。
加工ミスがあった場合、データの再取得・再加工といった手戻り作業が必要になります。さらに、誰もエラーに気付かず間違ったデータに基づく意思決定が行われるリスクもあります。
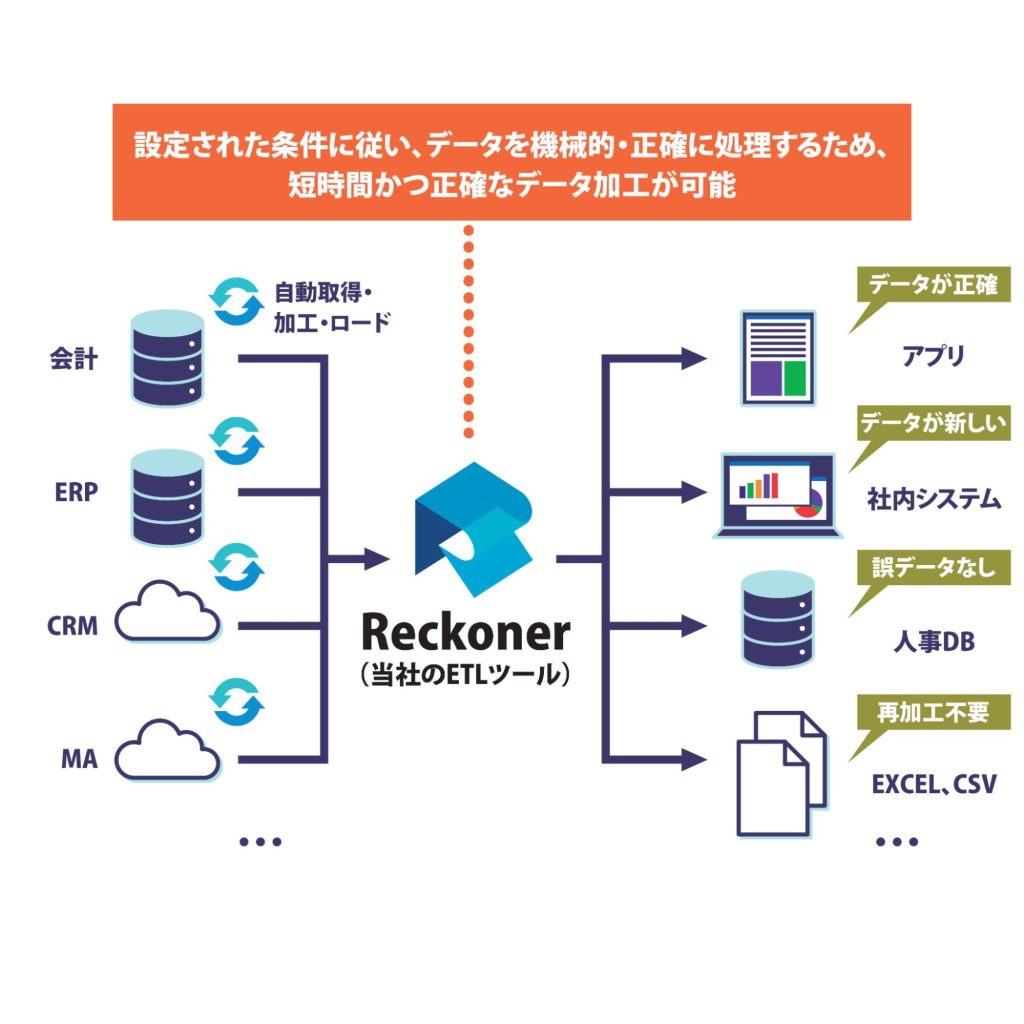
ETLを利用する場合、「元データ→ETL→別システム」という流れで機械的にデータを取得、変換・加工、そしてロードされます。人の手を介在しないので、あらかじめ決められた条件やロジックに基づいてデータが正しく処理できるため、ヒューマンエラーが発生しません。
3.データソースとの連携に必要な開発工数がゼロになる
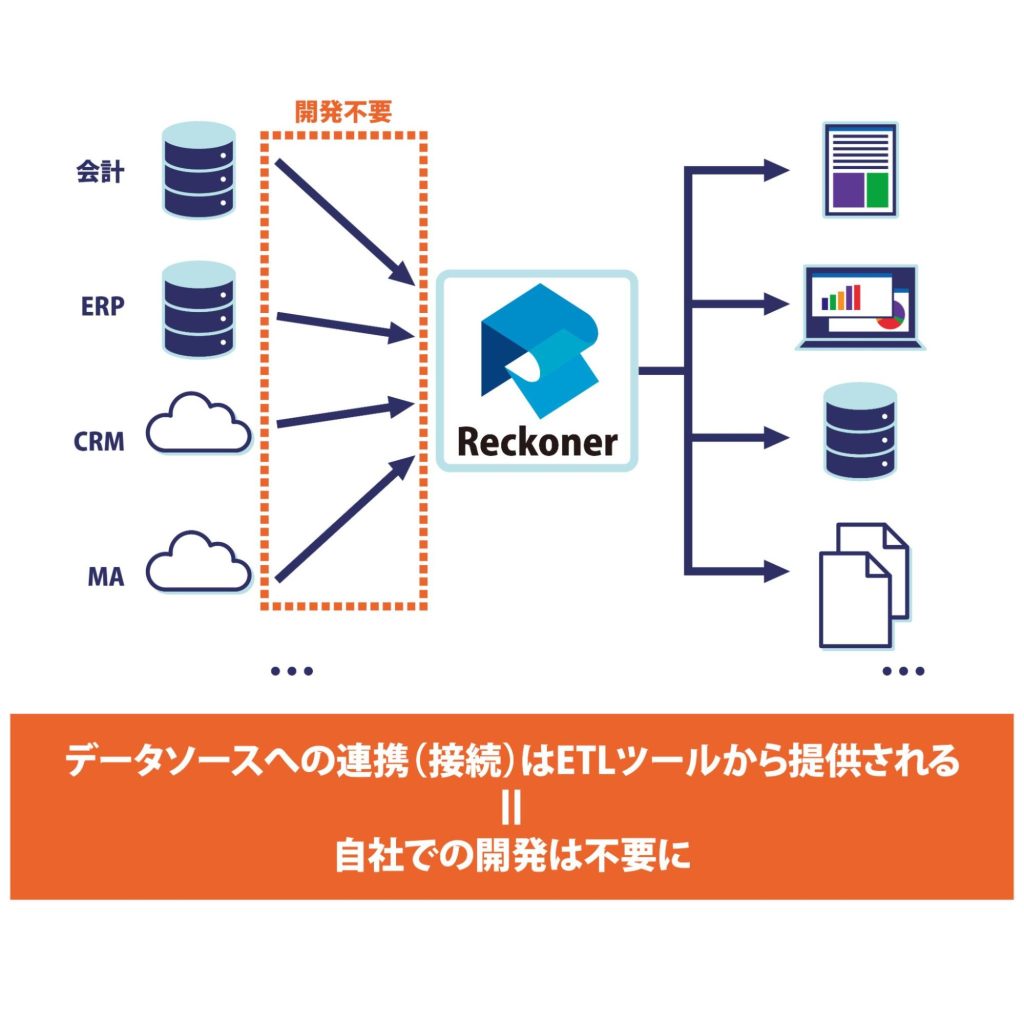
ETLツールを利用せずに、複数のデータソースと連携を行おうとした場合、データ連携を行う為の開発工数が必要となります。
例えば、AWS上のサービスとデータ連携を行う場合は、AWSのドキュメントを読み込んだ上で自社で開発するか、ベンダーに依頼する必要があります。
同様に、Google Cloud、Snowflake、Marketo、Salesforceなど、様々なサービスとデータ連携を行う場合、各サービスそれぞれについてデータ連携方法、開発工数、条件(費用含む)を確認する必要があります。
もしこの作業を社内で行おうとした場合は、かなり長期間に渡り、エンジニアのリソースをこの業務のために割く必要が生じ、他の業務に支障をきたします。
また、この業務をベンダーに依頼した場合は、相応の開発工数とコストがかかります。
ETLツールを利用した場合、データはいつでも接続可能な状態から利用ができるため、データ連携にかかる開発工数、ならびに開発期間がゼロになります。
4.データ連携先の仕様変更への対応工数がゼロになる
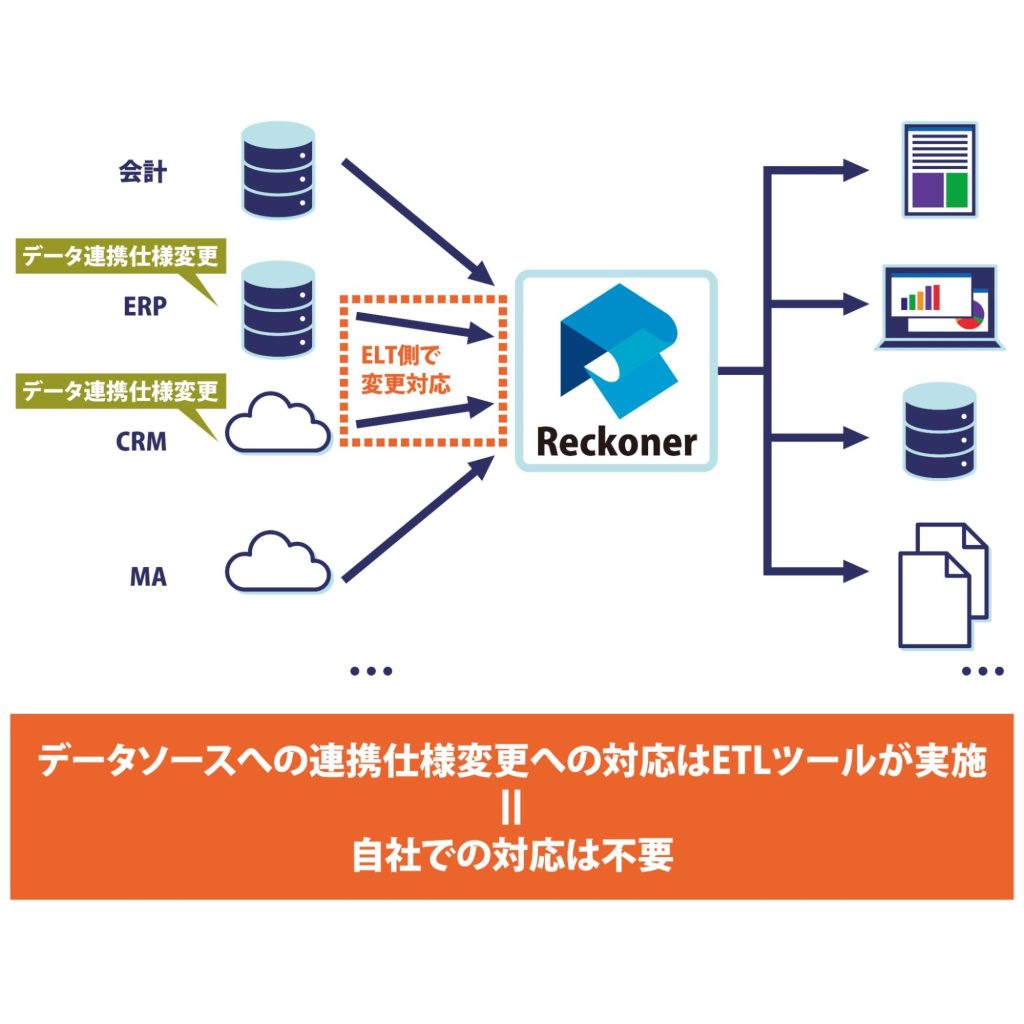
各サービスとのデータ連携は、最初に設定すれば完了、というわけではありません。
AWSやGoogle Cloud、Salesforceといった各種サービスが、データ連携の仕様を変更するたびに、修正する必要があるためです。
自社で開発したデータ連携基盤を運用する場合は大変です。仮にデータ連携先が5つあり、これらが毎年データ連携の仕様を変更した場合、年に5回の追加開発・修正が必要となります。
各サービスのデータ連携仕様が切り替わるタイミングまでに開発を終えられなかった場合は、翌日以降のデータ取得や加工が不可能となり、業務に支障をきたします。
そして、こうしたデータ連携の仕様変更は「毎年9月に変更します」というように、あらかじめ決まっているわけではありません。よって、「常にデータ連携仕様に関して変更が発表されないか」という情報を追いかけ続ける必要があることに加え、「変更が発表された」場合は日頃の業務をやりくりして、期日までに必ず修正を行わねばなりません。
ETLツールを利用した場合は、ETLサービスを提供する企業側で、データ連携先の仕様変更の対応が行われるため、データ連携先の仕様変更について全く意識しておかなくても、勝手に対応してくれます。
5. [サブスク型ETL] コストを平準化でき、トータルコストも節約できる
ETLツールは、うまく利用するとコストの平準化、ならびにトータルコストの削減に役立ちます。
まず、ETLツールは大きく分けて「買い切り型」と「月額費用型(サブスクリプション、サブスク)」があります。特にコスト削減に寄与するのは「サブスクリプション」のタイプです。導入企業のコストとその平準化にどのように寄与できるかについて、3つの観点で説明します。

・(A)導入コストが低い
導入コストが最も高いのは、「自社開発ETLツール」です。これは、自社で全て開発する場合もしくは、ベンダーに開発依頼する場合の両方で高コストとなります。
「自社の従業員が開発すれば低コストではないか」と思われる方もいるかもしれませんが、「自社でETLツールを開発する」ために別業務が行えなくなります。
そして、過去にETLツールを開発したことがある方を除き、自分で調べながらデータ連携サービスに問い合わせて開発を行うことになるため、開発効率も期待できません。
結果、ETLツールを開発できたとしても、全ての機能、優れたUX、都度発生するデータ連携仕様変更への完璧な対応、が行われているケースは期待できません。
残念な言い方をすると、時間とお金を大量に投下したあげく、既存のETLツールの劣化版を作ってしまう可能性が非常に高いのです。
次にコストが高いのが、「買い切り型ETLツール」です。多くの買い切り型ETLツールは、導入時にライセンス費用と初年度サポート費用を支払うのが一般的です。
つまり、テストだけ完了した時点で、少なくとも数百万円以上の金額をまとめて支払う必要があります。機能面、UX面、サポート面に問題がなかった場合でも、特に中小企業やスタートアップの場合はキャッシュフローが一時的に悪化することは避けられません。
これらと比べて導入時コストが最も安いのが「サブスクリプション型」です。導入時にかかる費用は、安価な月額費用のみです(月額費用に、サポート費用が含まれている場合がほとんどです)。
会社のキャッシュフローを傷めず、手軽に導入が可能です。
・(B)サービス解約が容易
ETLだけでなくITサービスは、テスト時には問題なかったが、実運用で使ってみた結果支障が生じるというケースは多々あります。
例えば、「データ量を増やしたらレスポンスが遅くなった」「サービスが安定しない」「使い勝手が悪く、ユーザー部門からは利用を拒絶されてしまった」といった具合です。
しかし、既にかなりのコストを支払いETLツールを開発・購入してしまった場合は、別のETL製品を探して乗り換えるのは容易ではありません。
こうした場合、多くの企業で「導入したがほとんど使われないツール」として放置されることになります。
これに対し、サブスクリプション型の製品は、もし使い始めてみて問題が生じた場合は短期間で解約が可能です。短期間(最低契約期間)で解約をした場合、買い切り型のように膨大なコストが生じることはありません。
・(C)サーバー調達・運用コストがゼロ
自社開発ETL、ならび買い切り型ETLのいずれも、物理サーバーもしくはクラウド上のサーバーで運用を行う必要があります。
物理サーバーであれば、ハードウェア調達コスト、ソフトウェア設定コスト、データセンター利用コストが別途必要です。そして、ETL製品の保守にかかる工数や費用だけでなく、サーバーの運用工数や費用も必要となります。
これに対して、サブスク型ETLの場合、月額費用に「ETL利用費用」「クラウドサーバー費用」「サポート費用」などが全て含まれているため、サーバーの調達・運用を意識する場面が全くありません。
「DataOps」と「ETL」
昨今、「DataOps」というデータ管理・運用アプローチに注目が集まっています。そして、DataOpsの中核ともいうべき要素の一つがETLです。
DataOpsとは
DataOpsとは、業務を通じてデータを活用するユーザーが、データ開発者と密にコミュニケーションをとりながらアジャイル開発的な手法を取り入れ、組織が目指すデータ活用を実現する手法です。この手法については、2010年代中盤に提唱され、以後広がりを見せています。
DataOpsは、あらゆる部門におけるデータ活用や、サイロ化や特定のベンダー依存からの脱却、コスト削減や効率性の向上といった目的のために、アジャイル開発手法の導入、データ基盤の整備、データ運用の自動化、データ品質の向上、分析ツールの導入などの手段を用います。
なお、DataOpsは「DevOps」から影響を受けていますが、「DataOps = DevOpsのデータ領域における実践」と言い切れるほど、内容的に共通しているわけではありません。
DataOpsにおけるETLの重要性
DataOpsにおけるETL利用の重要性をご理解頂くための、4つのポイントをご紹介します。
バッチプログラム作成を回避する
DataOpsにおいてETLは、データ品質を担保するために、あらゆるデータソースと接続し、大量にデータ変換処理を実施し、使える形にして出力するという役割を担います。
もしETLがなければ、データの変換処理のために「バッチプログラム開発」を行う必要があります。「データベースAのデータを取得して、このように処理して、データベースBに出力する」といったプログラムを何十、何百と開発し続けなければなりません。実際に多くの企業では、いまだにこのような「データ処理専用のバッチプログラム」を多数開発しており、その運用に苦しんでいます。
なぜなら、バッチプログラムは単に開発するだけでは終わらないためです。データソースや出力先の仕様変更があった場合は、追加での開発が必要となります。ユーザー部門から「データ変換内容」や「取得するデータ」の変更リクエストがあった場合も、修正が必要です。
もし、プログラム開発や修正を自社で行う場合にはエンジニアのリソースが必要です。外注の場合は都度「社内の承認プロセス」「外注費用」がかかります。プログラム開発に加えて、ドキュメント作成も必要です。また、SaaSなどのデータソースに接続する際に「API利用料」といった名目で追加費用がかかる場合もあります。
監査性を確保し、ブラックボックスを回避する
バッチプログラムによる問題は、開発費用ならびにリソースだけではありません。監査の観点からも問題があります。
大量のバッチプログラムが適切に開発、修正、保守されているかを、透明性をもって報告、共有、運用することは非常に難しいのです。特に社内で特定のエンジニアがバッチプログラムを管理し、ドキュメント作成が不十分である場合が顕著です。管理が不十分な場合、バッチプログラムは容易にブラックボックス化します。
ブラックボックス化したバッチプログラムは、「一見正しく動いているように見えても、本当に正しく動いているのか検証しようがない」「エンジニア退職時に正しく情報が引き継がれずトラブルになる」といったリスクがあります。結果として、企業の生命線とも言うべき「正確なデータの処理」に大きな打撃を与えかねません。
自動化とデータ品質向上を促進する
DataOpsが特に注力するキーワードに「自動化」「データ品質」があります。
自動化は、「ヒューマンエラーを防ぎ、データ処理を効率的かつ高速で実施する」上で欠かせない要素となります。バッチプログラムもある意味自動化と言えますが、管理が困難で属人的になるリスクがあるため、好ましいアプローチではありません。ETLでは、管理性や属人化といったリスクがないため、より進んだ自動化といえます。
データ品質は、データ管理と運用における基本中の基本です。しかし、「データ品質を維持するために、コストや速度が犠牲になる」ことは当然望ましくありません。「データ品質は非常に高いが、売上データの把握に2週間かかり、データ管理だけで何十人も働いている」というような場合、高コスト体質かつ迅速な意思決定が行えない組織となってしまいます。
ETLは、高度な自動化を実現しつつ、データ品質を担保できることに加えて、高速かつ低コストな処理が実現できます。
データの民主化を実現する
バッチプログラム開発における課題の一つは、ユーザー部門からのリクエストへの対応です。しかし、クラウド型のETL製品の一部は、優れたUI/UXを持つことから、ユーザー部門の担当者がデータ変換プロセスを自身で作成できます。
DataOpsの中核として考えられているのは、データサイエンティストのようなデータのスペシャリストではなく、事業部門のデータ利用者です。「ユーザーがデータより容易に分析できる環境を提供する」ことは、「データの民主化」と呼ばれ、DataOpsにおいても重視されています。
2016年のCrowdflower社(現Figure Eight社)の調査によると、データ管理において最も時間を費やされているのは「データ準備工程」であることが判明しています。データ準備工程の多くは、データへのアクセス権や操作の難易度の高さという観点から、データ管理部門でないと行えないのが一般的でした。そのため、ユーザーは「通常使っているデータ以外を用いて分析したくても、ハードルが高すぎて無理」という状態が続きました。
UI/UXに優れたクラウド型のETLを導入するということは、「必要なデータソース全てにあらかじめ接続されたデータ基盤に、ユーザーがアクセスできる」ことを意味します。そして、「データの取得、変換、出力」を自身で操作できるようになります。これこそが「データの民主化」です。
クラウドネイティブETL「Reckoner」を無料お試し
当社が提供するETL製品「Reckoner(レコナー)」は、単純なデータ加工から、複数のデータソースから取得したデータの複雑な加工まで、様々な要件に合わせてデータ変換を行うETL製品です。
非エンジニアでも簡単に利用できるよう、ドラッグ&ドロップでの直感的な操作を実現しているため、ETLの操作にかける時間を最小化し、本質的なデータ分析・データ活用により多くの時間を割けるようになります。

接続先は多数(データベース、クラウド基盤、SaaSなど)対応しています。主な対応製品は以下の通りです。

クラウドネイティブのETL製品「Reckoner」は、無料トライアルが可能ですので、ぜひお試しください。不明点があれば、スタッフがオンラインでご支援させていただきます。
ETLツールについて詳しく知りたい、ETLツールの選び方を知りたいという方はこちらの「ETLツールとは?選び方やメリットを解説」をぜひご覧ください。







