【用語集】データレイク

データレイクは、あらゆる形式(構造化データ、非構造化)のデータを格納できるストレージリポジトリです。ビッグデータを活用する時代の到来とともにデータレイクは注目視され、多様化するデータを一括管理するために活用されるようになりました。
本記事では、DB(データベース)やDWH(データウェアハウス)との違いについて触れながら、データレイクとは何か解説していきます。
データレイクが必要な理由
Aberdeen社の調査によると、データレイクを実装している企業は、未実装の他企業に対して収益成長率が 9% 上回っているというデータがあります。*
データレイクに保存されたデータをもとに、データ分析や機械学習を行うことで、生産性の向上や顧客満足度の向上、合理的な意思決定ができるようになり、結果として事業の成長に繋がっていると考えられます。
データレイクの導入には手間や運用コストはかかりますが、今後のビジネス成長につながるデータ基盤整備と考えると、「正しく活用される」のであれば「割に合う投資」となると考えられます。
【データレイクの特徴】DBやDWHとの違いについて
データレイクの大きな特徴は、データをそのままの形で保存できることです。構造化(エクセル・CSVなど)、非構造化(画像・動画・音声など)問わずデータを管理しておきたいときに役立ちます。
データを生の状態で保存して活用できるため、柔軟性が高く、帰納的アプローチを行う機械学習などに向いており、今ではビッグデータの管理になくてはならない存在です。
以下、混合しやすいDBやDWHとの違いについて解説していきます。
DBとの違い
DB:構造化データを管理する
データレイク:構造化・非構造化データを管理する
一般的なDBは、行と列で定義(構造化)されたリレーショナルデータを管理します。これに対し、データレイクはあらゆるデータを生データの状態で管理するのを得意とするため、この点が両者の違いです。
また、DBは構造化データを扱っているため、データ管理がしやすく、必要に応じてすぐに集計・解析することが可能です。しかし近年、ビッグデータのような非構造化データの活用が重要視されるにつれ、従来のリレーショナルDBではなく、データレイクが用いられる機会が増えてきました。
DWHとの違い
DWH:データ分析しやすい形に整理してから格納する
データレイク:生データを大量に管理しておく
DWHはデータを格納する前段階で、データを成形しなおします。DWHはデータ活用することを前提として用いられるため、目的に合った設計を行ったうえでデータを成形し、格納しておきます。データレイクは「生データを大量に保管すること」を目的としているため、データの保管方法や目的という点で両者は異なります。
また、データレイクは構造化するコストがかからないため、DWHよりも安価に大量のデータを保管できるという特徴があります。
DBとDWHの違いについては以下の記事で詳しく説明しております。
参考記事: 用語集DWH(データウェアハウス)
https://reckoner.io/blog/dwh
データレイクが沼になるリスクとDataOpsの可能性

データレイクは使いこなせば便利な反面、どんなデータが入っているか把握不能となる「データ沼化(沼化)」しやすいというリスクもあります。ここでは、沼化のリスクとDataOpsの可能性について解説します。
データレイクの沼化
データレイクは、定型データならびに非定型データをそのままの形で大量に格納できる点がメリットである反面、「どんなデータが格納されているか分からない」「誰がどのような必要性でデータを保存しているか分からない」「必要なデータをすぐに入手できない」といった問題、いわゆる「沼化」のリスクを抱えています。「データスワンプ」とも呼ばれます。
データレイクは、あらゆるデータを「とりあえず蓄積」する特性を持ちます。データを保存する前に、あらかじめ使い道を考えることはせず「後で何かしらに使える」という考えのもと大量のデータを蓄積するというケースがほとんどです。
データレイクに保存されたデータは、正しい用途が見出されたタイミングでデータサイエンティストなどがその分析に当たります。データサイエンティンストはデータの専門家ですが、それでもデータレイクに保存されたデータを扱いやすい形に整形する前準備には膨大な時間がかかります。また、データサイエンティストのような専門家に「データレイクのデータを取り出して、使えるようにする」という単純作業を行わせるのは、業務効率や人件費の面で問題があります。
つまり、データレイクにストックされているデータを扱うためには時間も工数も必要で、すぐに活用できない状態です。また、格納されるデータが増えれば増えるほど、その弊害はますます深刻化してしまい、「データ活用するには適さない」という状況に陥ります。
DataOpsに取り組むためには
前項で述べたようなデータの沼化を避け、データ活用を効果的に行うためにはDataOpsの観点を踏まえてデータ環境を整備しておく必要があります。
DataOpsとは、開発者側と運用者側を統制するDevOpsの考え方を、データの活用に応用した考え方です。データフローの確立と、組織全体で「日次」かつ「継続的」なデータ利活用を強調して進める考え方で、組織におけるデータ利活用のプロセス最適化を目的としています。
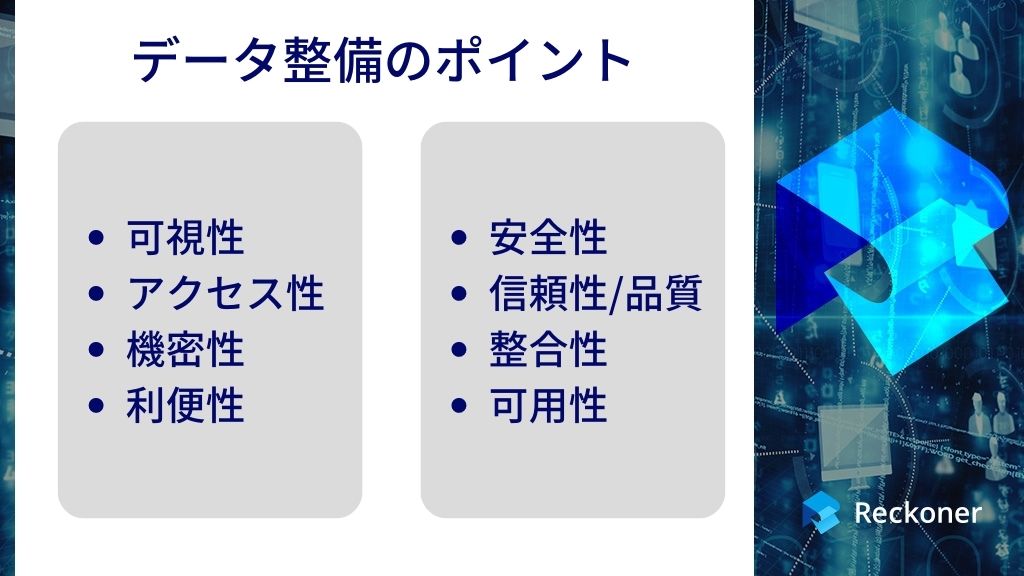
具体的に以下の点に注意して整理しておくと良いでしょう。
可視性
いつ、どこから収集したデータなのかがすぐわかるようにしておくことで、必要なデータを探しやすくなります。また、検索しやすい環境を整えておくとさらに便利に活用できるでしょう。
可視性を上げるためには、データカタログの作成が効果的です。
アクセス性
データに簡単にアクセスでき、便利に使えることも重要なポイントです。例えば、特定の端末からしかアクセスできないデータが多すぎる場合、データ活用の頻度が下がってしまう可能性があります。
オフィスのパソコンだけでなく、クラウドを通じてスマートフォンやタブレットからもアクセスできるようにしておくとさらに便利です。
機密性
多くのデータに簡単にアクセスできる状態は便利ですが、一方で機密性が問題となります。例えば、人事評価に関する情報をストックする場合、そこにアクセスできるのは限られた人だけに設定する必要があります。
利便性
できるだけ手間をかけずにデータを利用できる環境を整えておくと、データを活用しやすくなります。DWHのように事前の加工までは必要ありませんが、例えば一緒に使われることが多いデータを近い場所に置いておくなどのちょっとした工夫でも利便性の向上が可能です。
安全性
データを活用するためには、安全性も重要です。例えば、データレイクに外部からアクセスできてしまうような状態は安全とは言えません。利便性やアクセス性を重視するあまり、安全性がおろそかになることがないよう注意してください。
信頼性・品質
情報の信頼性や品質も重要です。信頼性や品質が低いデータを使った分析では、不正確な結果が発生しビジネスの方向まで誤ることになりかねません。データを収集する際には、信頼性や品質が十分なものかどうかを考えておきましょう。
信頼性が低いデータが増えると、沼化のリスクが高まります。余分なデータを収集しないことも、データレイクの沼化を避けることにつながります。
整合性
1つのデータが他のデータと矛盾しないよう、整合性を保つことも重要です。データに整合性がないと、分析にどのデータを使ったらよいのかわかりにくくなるため、活用の頻度が下がってしまいます。
例えば、途中でデータ収集の基準を変更したり、同時に収集すべきデータを別々に集めていたりするとデータの整合性が取れなくなる可能性があるため注意してください。
可用性
可用性とは、必要な時にすぐ使える状態をキープしておくことを指します。例えば、たびたびシステムがダウンしてしまって使えない時間が長かったり、トラブルの際にデータレイクの中身がすべて消えてしまうような運用は可用性が高いとは言えません。
可用性が低いと、データを活用しにくくなります。システムダウンの原因を突き止め対策を講じる、データのバックアップを用意するなどの方法で可用性を高めておきましょう。
データレイクがデータの整形を後回しにするのに対して、DWH(データウェアハウス)ではデータを必要な形に変形してから格納します。単純に変形するタイミングの違いと感じられるかもしれません。しかしDataOpsの概念にのっとれば、事前にデータを整形し、いつでも使える状態にしておくことが非常に重要です。データ活用の頻度や取り組み状況に応じて、データの持ち方自体を検討し直しても良いのではないでしょうか。
これからのデータビジネスでは、従来のように「ビッグデータを集めておけば今後何かに役立つ」という考え方よりも、データの扱いや活用方法を前もって考えておくことが重要です。
最後に:データ分析でお悩みなら弊社までお問い合わせを
ビッグデータの活用や社内でサイロ化しているデータを活用して、今後のビジネスに活かしていきたいと考えている企業様は、ぜひ弊社にお任せください。
「データ活用したいが何から始めればよいか分からない」といった質問でも構いませんので、お気軽に問い合わせいただければ幸いです。
貴社の状況に合わせた提案をさせていただきます。







